
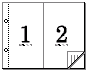
a2ps -p ファイル名 | psnup -2| lp -y flip
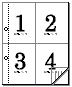
a2ps -p ファイル名 |psnup -4 | lp
| cd | ホームディレクトリに移動 |
| cd zzz | あるディレクトリ(例:zzz)に移動 |
| cd .. | 一つ上のディレクトリに移動 |
| ls | ディレクトリ中のファイル一覧を表示 |
| ls -l | ディレクトリ中の詳細なファイル一覧を表示 |
| ls -la | ディレクトリ中の詳細なファイル一覧(隠しファイル含む)を表示 |
| pwd | 現在いるディレクトリの確認 |
| cat zzz | ファイル(例:zzz)の内容確認(止まらない) |
| less zzz | ファイル(例:zzz)の内容確認(止まる)
スペースキーで次に、qで終了 |
| cp A B | ファイルAをファイルBにコピー |
| cp -r A B | ディレクトリAをディレクトリBにコピー |
| mv old new | ファイル名をoldからnewに変更(例:old と new) |
| mv zzz .. | ファイル(例:zzz)を一つ上のディレクトリに移動 |
| mv ファイル名 ディレクトリ名 | ファイルをディレクトリに移動 |
| rm ファイル名 | ファイルの削除 |
| rm -rf ディレクトリ名 | ディレクトリの中身ごと削除 |
| rmdir ディレクトリ | ディレクトリの削除 |
| mkdir ディレクトリ名 | ディレクトリの作成 |
| man コマンド | コマンドの利用説明 |
・鍵を作る
nile% ssh-keygen
-------- リターン
パスフレーズを2回打つ
・ログインしたいマシンに公開鍵を置く(identity.pub)
dream% mkdir .ssh
dream% scp nile:/.ssh/identity.pub .ssh
drem% mv identity.pub authorized_keys
・エージェントの起動
nile% ssh-agent
nile% ssh-agent
setenv SSH_AUTH_SOCK /tmp/ssh-yuka/ssh-20274-agent ;
setenv SSH_AGENT_PID 20275 ;
echo Agent pid 20275 ;
nile% setenv SSH_AUTH_SOCK /tmp/ssh-yuka/ssh-20274-agent ;
nile% setenv SSH_AGENT_PID 20275 ;
nile% echo Agent pid 20275 ;
・秘密鍵の登録
nile% ssh-add
パスフレーズを打つ
・次回のログインにも反映するように.cshrcに書く
.cshrcに以下の2行を新しいのに修正
setenv SSH_AUTH_SOCK /tmp/ssh-yuka/ssh-20274-agent
setenv SSH_AGENT_PID 20275
一度ログアウトして、
% ssh dream
これでパスワードを聞かれなければOK
---------------------------------------------------------------
SSHエージェントの再起動方法:
・まず、前の環境変数を消しておく
% unsetenv SSH_AUTH_SOCK ; unsetenv SSH_AGENT_PID ;
・あたらしいエージェントの起動
% ssh-agent
setenv SSH_AUTH_SOCK /tmp/ssh-yuka/ssh-20274-agent ;
setenv SSH_AGENT_PID 20275 ;
echo Agent pid 20275 ;
% setenv SSH_AUTH_SOCK /tmp/ssh-yuka/ssh-20274-agent ;
% setenv SSH_AGENT_PID 20275 ;
% echo Agent pid 20275 ;
・秘密鍵の登録
% ssh-add
パスフレーズを打つ
・できているかどうか確かめ
% ssh dream
これでパスワードを聞かれなければOK
・次回のログインにも反映するように.cshrcに書く
.cshrcに以下の2行を新しいのに修正
setenv SSH_AUTH_SOCK /tmp/ssh-yuka/ssh-20274-agent
setenv SSH_AGENT_PID 20275
一度ログアウトして、
% ssh dream
これでパスワードを聞かれなければOK
・cronを動かしているのなら、それも修正
(数字2個所)
% crontab -e
0 5 * * *
env SSH_AUTH_SOCK=/tmp/ssh-yuka/ssh-20274-agent
^^^^^
env SSH_AGENT_PID=20275 /usr/local/bin/rsync -e /usr/local/bin/ssh
^^^^^^
........
% groff -man /opt/ImageMagick/man/man1/convert.1 > convert_man.ps
% lpstat -a % lpc lpc > status
枠線をつけて4分割 % cat bababa.ps |psnup -d -4 | lp 1.5cmマージンをつけて4分割 % cat bababa.ps |psnup -m1.5cm -4 | lp
nileでのプリントアウトメモです。
|
a2ps -p ファイル名 | lp |
|
a2ps ファイル名 | lp -y flip a2ps -p ファイル名 | psnup -2| lp -y flip |
|
a2ps ファイル名 |psnup -2 | lp a2ps -p ファイル名 |psnup -4 | lp |
|
a2ps -w ファイル名 | lp -y flip |
|
a2ps -w ファイル名 |psnup -2 | lp |
% ln -s A B
% xmllint --noout --valid zzz.xml |& lv -Iu8 | cat bsh風に(Makefileなどで使う) % xmllint --noout --valid zzz.xml 2>&1 | lv -Iu8 | cat
% qkc -e bababa.txt もしくは % nkf -e bababa.txt > bababa.txt.e % mv bababa.txt.e bababa.txt UNIX(EUC,LF)→ Windows(Shift JIS, CR/LF) % nkf -sc oldfile > newfile Windows(Shift JIS, CR/LF) → UNIX(EUC,LF) % nkf -ed oldfile > newfile
find . -name \*~ | xargs ls -l
find . -name \*~ -exec ls -l {} \;
ls -l `find . -name \*~`
bababa ……… 共通に含まれる行
rarara …………………………… file1.txtだけに含まれる行
tatata ………………… file2.txtだけに含まれる行
zzzz ………… 共通に含まれる行
file.txt の先頭10行を出力 % head file.txt file.txt の先頭100行を出力 % head -100 file.txt
file.txt の末尾10行を出力 % tail file.txt file.txt の末尾100行を出力 % tail -100 file.txt file.txt の2行目以降のを出力 % tail +2 file.txt
% gzip -cd ???.tar.gz | tar xvf - % gzip -d ???.gz % uncompress ???.Z % unzip ???.zip % tar xvf ???.tar (解凍の確かめ % tar tf ???.tar | more) % lha -x ???.lha
圧縮なし % tar cf /tmp/bababa.tar ディレクトリ
% tar cf - ディレクトリ | rsh dream dd of=作るファイル名.tar
圧縮あり % tar cf - ディレクトリ | gzip -c > /tmp/bababa.tar.gz
% lha a ファイル名.lzh ディレクトリ
% nl -ba ファイル名 > 行番号つきファイル もしくは % cat -n ファイル名 > 行番号つきファイル
40字で改行する。 % nkf -e -f40 bababa.txt > 改行付ファイル fold を 使うこともできる。ただしcosmoでは日本語が入っているとうまくできない。 % fold ファイル名 > 改行付ファイル 20字で改行 % fold -w20 ファイル名
% sed "s/検索文字列/置換文字列/g" ファイル名 % cat ファイル名 | sed -e "s/検索文字列/置換文字列/g" (番外編) カレントディレクトリ以下のHTMLファイルの一括置換(元のファイルは *.bakに) % find . -type f -name '*.html' | xargs perl -i.bak -pe \ 's#old#new#gi' % find . -type f -name '*.html' | xargs perl -i.bak -pe \ 's#<meta http-equiv="Content-Type" content="text/html; charset=ISO-2022-JP">#<meta http-equiv="Content-Type" content="text/html; charset=EUC-JP">#gi' 行頭の行番号を消す。 perl -i.bak -pe 's#^\s+\d+\t##' rei1.c sed 's/^ .[0-9] //' rei1.c
例: ”:”を区切りにして、1 番目と5番目のデータだけを抜き出す。
抜き出したレコードはタブで区切って出力
% awk -F':' '{print $1 "\t" $5;}' ファイル名
% tr -d '\n' bababa.txt > zzz.txt
日本語文字を1文字として数える。(ただし改行も1文字として数える) % wc -m bababa.txt 改行を除いて文字数を数える % tr -d '\n' bababa.txt | wc -m
% wc -l bababa.txtwc は他にも単語数を数えたりできます。
% sort ファイル名 > ソート済みファイル名
例) ファイルの大きさでソート
% ls -l | sort +4
ソートして重複を消す。 % sort ファイル名 | uniq
wget -r -np -l 1 http://cosmo.ulis.ac.jp/~yuka/
(プロキシを使わない) wget -r -np -Y off -l 0 http://cosmo.ulis.ac.jp/~yuka/
lynx -dump ????.html |nkf -e > ????.txt
右回転 % convert -rotate 90 bababa.xwd bababa90.xwd 左回転 % convert -rotate -90 bababa.xwd bababa90.xwd
% convert bababa.xwd bababa.ps % psresize -Pletter -pa4 bababa.ps zzz.ps
file.gif 75%縮小したファイル file75.gif を作成。 % convert -geometry 75%x75% file file75
% mogrify -format gif *.bmp
% gs -q -dNOPAUSE -sDEVICE=ppmraw -dTextAlphaBits=4 -dGraphicsAlphaBits=4 \ -sOutputFile=image-%d.ppm genkou.ps < /dev/null % foreach i ( image-*.pbm )
? echo $i
? ppmtogif < $i > $i:r.gif
? end
% echo $環境変数
% ypcat passwd
( du -s /usr/users/yamalab/* ; du -s /usr/users/others/* ) | sort -nr
% chown yuka yuka
% chgrp filename grpname
% crontab -l
% crontab -e
IE:Ctrl + F5 NN and Mozilla:Ctrl + Shift + r